Hugging Face’s AI agent glossary makes harness, scaffold, and skills easier to compare


Hugging Face’s new agent glossary turns fuzzy agent terminology into a practical checklist for choosing frameworks, skills, memory, and tool loops.
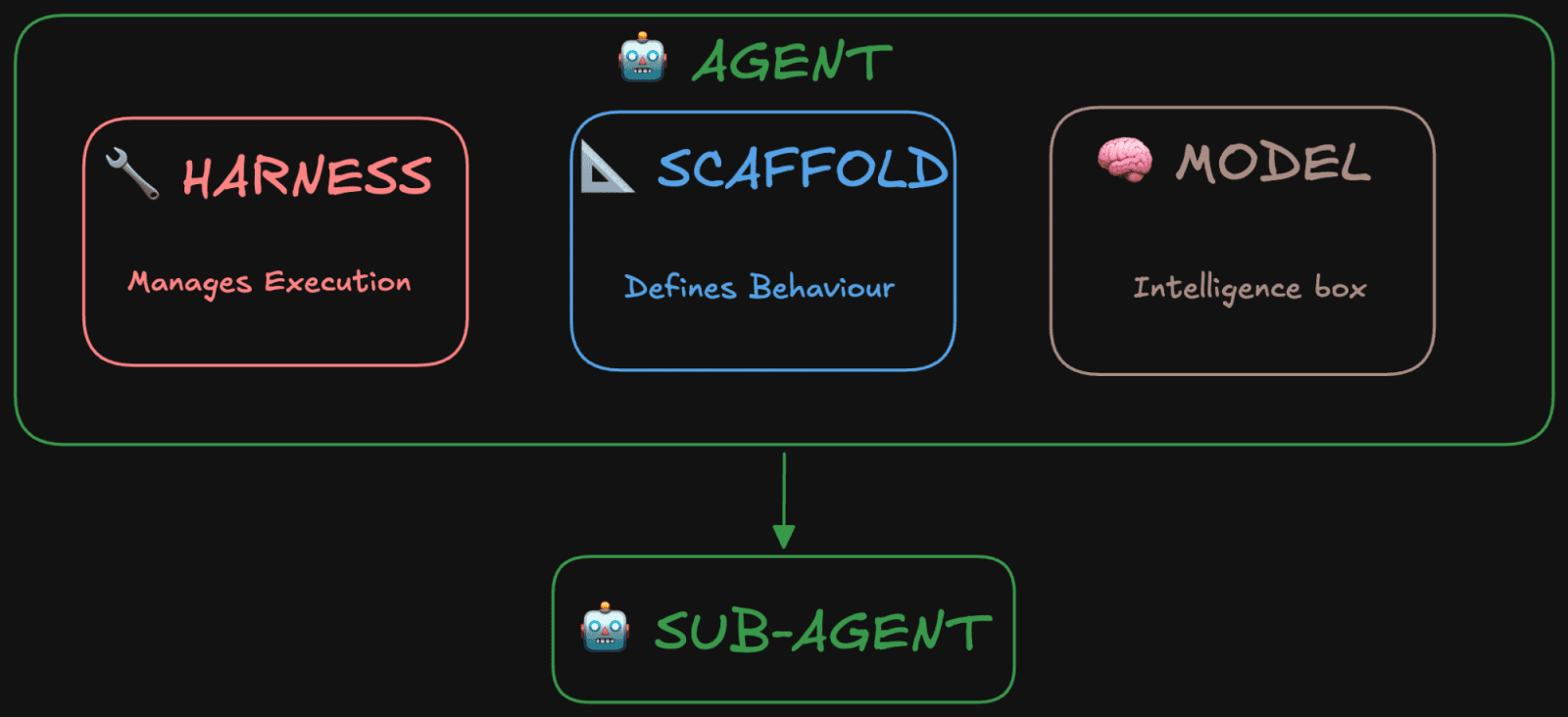
Hugging Face published a practical AI agent glossary that explains overloaded terms such as model, scaffolding, harness, context engineering, tool use, skills, sub-agents, rollout, and reward. The useful part is not another definition of “agent”; it separates the model from the layers that make the model act in a loop. For builders comparing Claude Code, Codex, OpenAI Agents SDK, MCP tools, or custom workflows, that vocabulary helps clarify what is actually being bought, built, or debugged.
Key takeaways
- Hugging Face frames an agent as a model wrapped by scaffolding and a harness, with the harness handling the execution loop and tool calls.
- The glossary distinguishes tools, skills, and sub-agents: tools are actions, skills package repeatable task knowledge, and sub-agents can reason independently.
- Context engineering is treated as an ongoing runtime design problem, not just a longer prompt or a bigger context window.
- Anthropic’s agent guidance independently supports the same practical split between predictable workflows and more autonomous agents.
- OpenAI’s Agents SDK documentation shows how these ideas map into concrete primitives: agents, handoffs, guardrails, sessions, tools, tracing, and sandbox agents.
Practical LinkLoot angle
The glossary is useful as a buying and implementation checklist. Before adopting a new agent product, ask whether the vendor is improving the model, the harness, the scaffold, the tool interface, the memory layer, or the evaluation loop. Those are different risks: a better model may improve reasoning, while a better harness may improve stopping conditions, retry behavior, traceability, and human review.
| Decision point | What to compare | Why it matters | Source anchor |
|---|---|---|---|
| Harness vs. model | Is the product mostly a model upgrade or an execution loop? | Two tools using similar models can behave very differently because their harnesses make different choices. | Hugging Face glossary |
| Workflow vs. agent | Is the job a fixed path or open-ended tool use? | Anthropic recommends workflows for predictable tasks and agents when flexibility is required. | Anthropic guidance |
| Skills vs. tools | Is repeatable knowledge packaged, or is it just a callable function? | Skills can reduce setup friction, but they also need review because they bundle instructions and assumptions. | Hugging Face glossary |
| Guardrails and sessions | Are validation, memory, handoffs, and tracing first-class? | OpenAI’s SDK exposes these as runtime primitives rather than leaving every team to rebuild them. | OpenAI docs |
A practical example: if a coding assistant fails after five tool calls, calling it a “bad model” may be the wrong diagnosis. The issue could be missing tool documentation, weak context management, no retry policy, no eval harness, or a scaffold that hides the project’s actual constraints. The glossary gives teams language for that postmortem.
What to verify before you act
First, check whether your target tool exposes its harness behavior: logs, traces, stop reasons, retries, sandbox limits, and human approval points. Second, verify whether “memory” means short-term context, external retrieval, persistent user preferences, or a session store, because each option has different privacy and debugging implications. Third, review any skill or agent package as untrusted operational content before installing it; a skill can silently change how an agent interprets a task even when it is not a traditional executable dependency.
For teams building reusable automation, pair this glossary with LinkLoot’s guide to AI workflow automation so terminology turns into concrete review criteria instead of slideware.
Source check
Hugging Face is the primary source for the glossary and specifically defines model, scaffolding, harness, agent, context engineering, tool use, skills, sub-agents, and training terms. Anthropic independently explains the workflow-versus-agent distinction and warns that agentic systems trade latency and cost for flexibility. OpenAI’s Agents SDK documentation corroborates the implementation side by listing runtime primitives such as agent loops, handoffs, guardrails, sessions, tracing, and sandbox agents.
It is the execution layer that calls the model, handles tool calls, routes results back into context, and decides when the run should stop.