Hugging Face Shows How to Benchmark Whether Tools Are Agent-Friendly


Hugging Face published an agent-evaluation harness that tests whether coding agents can use a library efficiently, not only whether they reach the right answer.
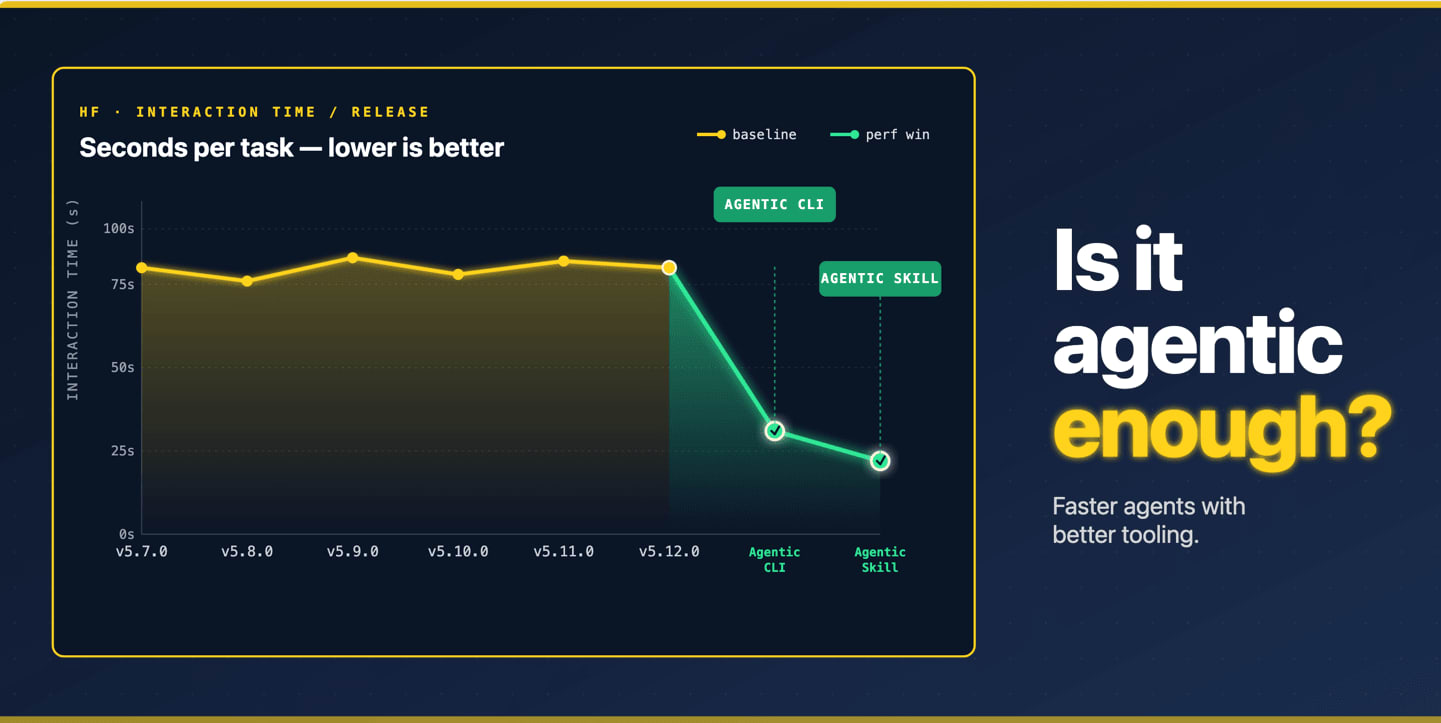
Hugging Face published a practical benchmark for testing whether AI agents can use developer tools efficiently. The project, called agent-eval in the linked repository, measures the path an agent takes through a library: commands used, tokens spent, elapsed time, errors, and whether the final answer matches the expected result. Its reference study uses transformers to show that a CLI and Skill can help large open models while hurting smaller models in some tasks.
Key takeaways
- The benchmark checks more than correctness: it records effort, trace behavior, token usage, time, errors, and marker adoption such as CLI use versus Python API use.
- Hugging Face ran the reference study across model sizes, library revisions, and three access tiers: bare install, cloned repository, and packaged Skill context.
- The Skill tier pushed larger models toward the new
transformersCLI, but some smaller Qwen3 runs became more expensive or less accurate. - The repository includes a static report workflow and uses Hugging Face Jobs to fan out model, revision, and task matrices.
- The security model matters: the harness is meant for trusted local benchmarking and warns against unreviewed code, leaked environment secrets, and unsafe trace reuse.
Practical LinkLoot angle
This is useful for anyone shipping tools that AI agents are expected to drive. A normal unit test tells you whether the library works. An agent-use benchmark tells you whether a model finds the right entry point, follows current docs, avoids obsolete APIs, and reaches the answer without burning unnecessary turns.
For LinkLoot readers building agent workflows, the practical move is to treat agent-facing documentation as a testable interface. Add one or two common tasks, define the expected result, and compare how different models behave with your README, examples, CLI, and Skill file. If a smaller model reads the wrong files or invents a non-existent tool call, that is a product bug, not only a model weakness.
| Option | Best use | Limitation | Source |
|---|---|---|---|
agent-eval | Measuring how agents use a library across models and revisions | Trusted local benchmarking only; runs can execute code | GitHub repository |
| Standard unit tests | Verifying deterministic library behavior | Does not show agent navigation cost or doc confusion | Project test suite |
| Manual agent trials | Quick sanity checks before a release | Hard to compare across models and commits | Local workflow |
| Static docs review | Improving examples and API wording | Cannot prove a model will choose the intended path | Docs and README |
What to verify before you act
Read the security notes before running the harness. The linked security file says agent runs can execute shell commands and can expose environment secrets, local paths, prompts, and trace content. Use a clean shell with minimal credentials, run only against repositories or revisions you trust, and treat generated traces as untrusted data before publishing or feeding them back into another model.
Also verify whether your use case needs exact-match scoring. Hugging Face focused on deterministic tasks for this study, which works well for classification, transcription, and similar checks. Workflows that rely on judgment, design quality, or multi-step business decisions will need a different scoring layer before the numbers mean much.
Why this beats another generic agent leaderboard
Most agent benchmarks rank the model. This one tests the tool surface too. That distinction matters because an agent can fail for reasons a maintainer can fix: missing examples, ambiguous CLI names, stale docs, oversized context, or a Skill that makes a small model call something as if it were a registered tool.
The useful question is not "which model wins?" It is "what did this model have to do to use my software?" That answer can change a release decision, especially when a change helps stronger models while making smaller models slower or less reliable.
It is a benchmarking harness for measuring how coding agents use a library, including correctness, time, tokens, errors, traces, and behavior markers.
For more agent-tool selection and workflow design notes, see LinkLoot's guide to AI agent tools.